Add Autonomy Last¶
A core challenge of using LLM's to build reliable automation is calibrating how much autonomy to give to models.
Too much, and the program loses track of what it's supposed to be doing. Too little, and the program feels a bit too, well, ordinary1.
Autonomy first vs autonomy last¶
An implicit strategy question when building with LLMs is autonomy first or autonomy last:
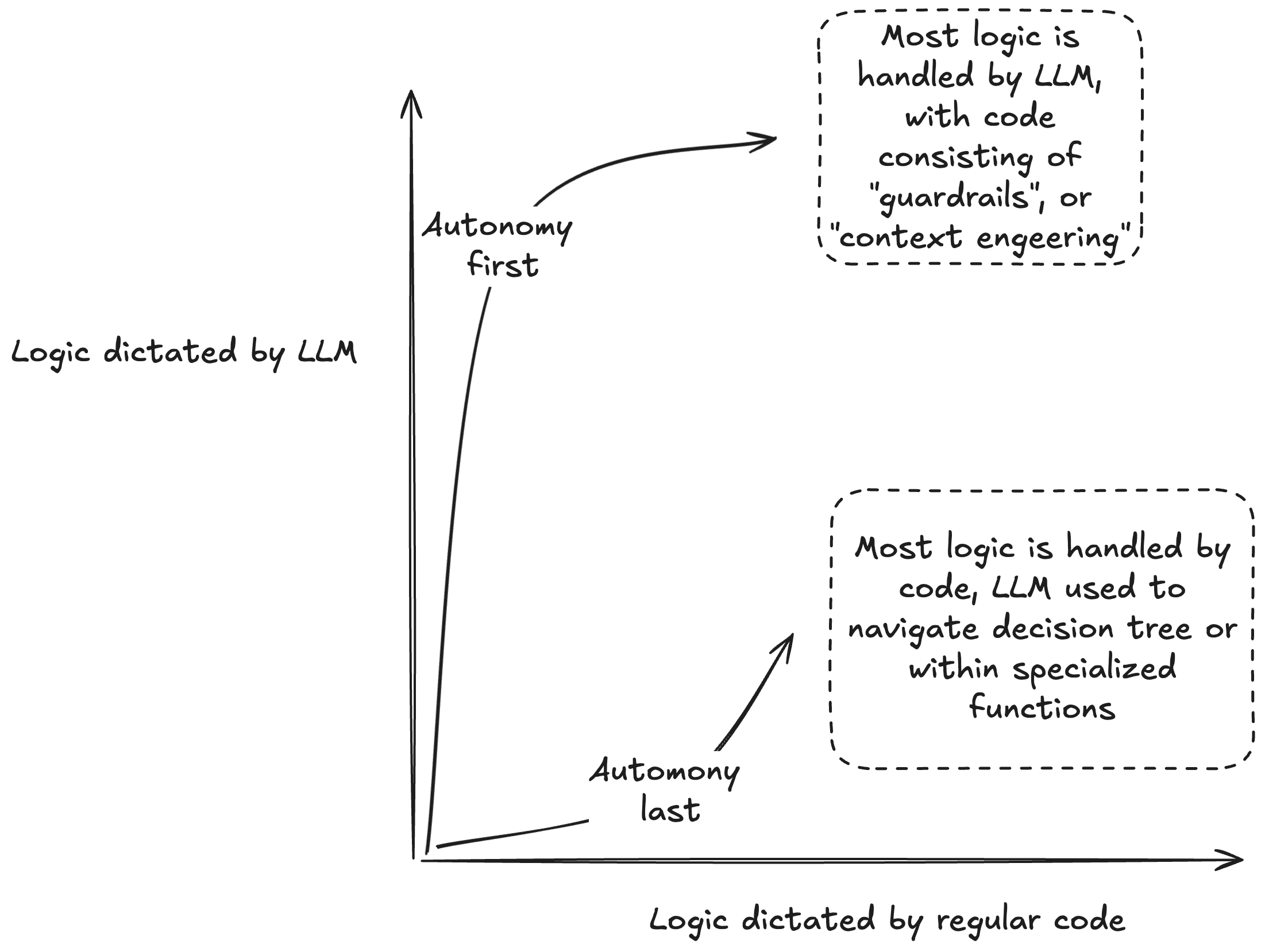
All of the major LLM-specific programming techniques are firmly autonomy first strategies:
- MCP surfaces a wide variety of functionality the program can have, and lets the LLM decide which to use
- Guardrails add some light buffers around the LLM to prevent it from causing too much trouble.
- Prompt engineering describes the alchemy of whispering just the right phrases to your LLM to get the behavior you want.
- Context engineering begins to stress programming to deliver only relevant information to LLMs at critical points in program execution
All of these:
- Start with a maximally autonomous program
- Adjust context, tools, and prompts until you narrow down behavior as desired.
All have similar issues when scaling in size and complexity:
- Program behavior changes too much when switching between models
- The LLM gets confused, and either hallucinates data or misuses tools at its disposal
When problems are encountered, programmers tend to attempt to repair by adding more prompting. But this is a duct tape response: a prompt that clarifies for one model might confused another.
Autonomy last, on the other hand, maximizes the logic that can be handled by code, then adds autonomous functions. This approach strives to keep the tasks delegated to LLMs simple. As the program grows in size and complexity, the programmer can closely monitor encapsulations and keep behavior consistent.
Case study: Building Elroy, a chatbot with memory¶
I wanted to build an LLM assistant with memory abilities, called Elroy. My goal was to make a program that could chat in human text. My ideal users are technical, capable and interested in customizing their software, but not necessarily interested in LLMs for their own sake.
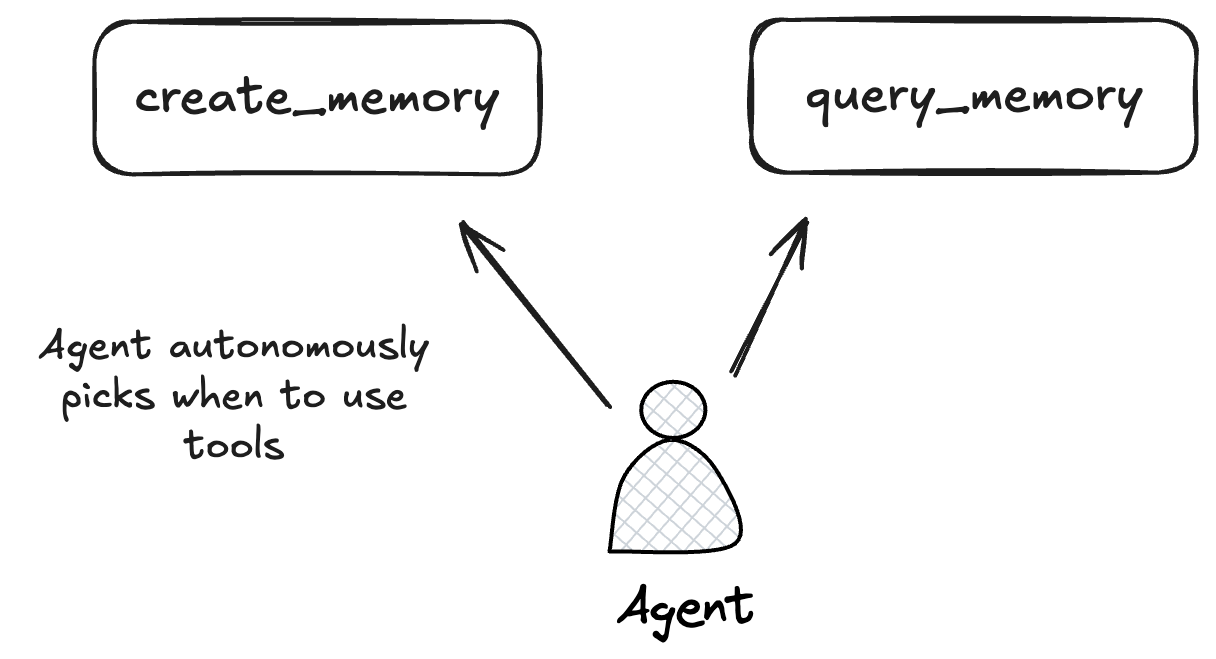
Approach #1: "Agent" with tools¶
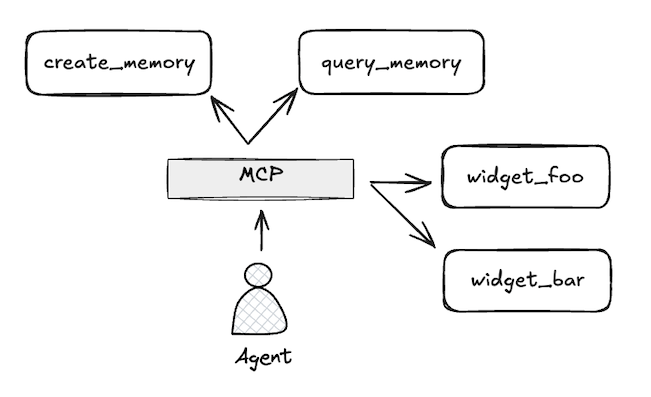
The first solution I turned to, which many people have done, is build an agent loop with access to custom for creating and reading memories:
Approach #2: Model Context Protocol (MCP)¶
There's now a handly tool for builders like this: MCP. There are many implementations of my memory tools available via MCP, in fact smithery.ai lists one from Mem0 on it's homepage:
Now, an (in theory) lightweight abstraction sits between my program and it's tools:
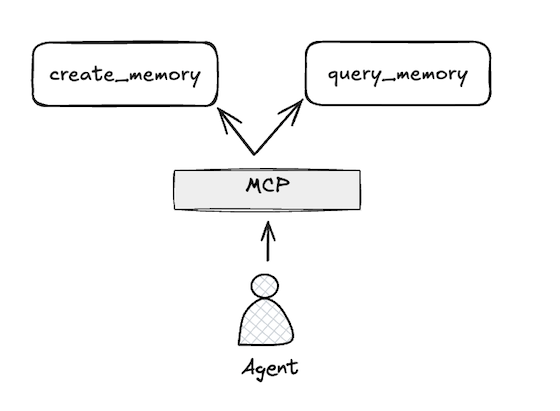
This suggests extending my application via picking from a library of MCP's:
Agentic trouble¶
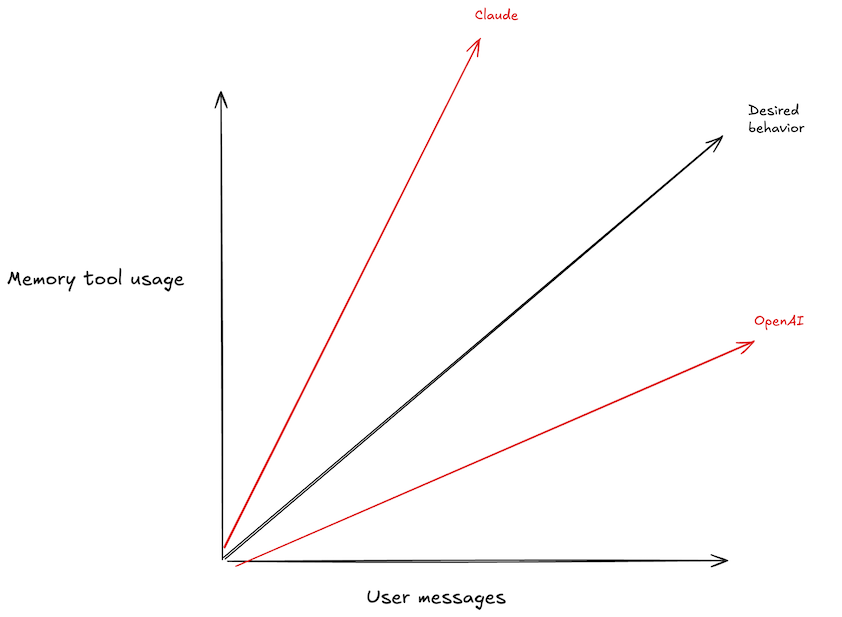
I got my memory program working pretty well on gpt-4. At first it wasn't creating or referencing memories enough, but I was able to fix this with careful prompting.
Then, I wanted to see how Sonnet would do, and I had a problem2: the program's behavior completely changed! Now, it was creating a memory on almost every message, and searching memories for even trivial responses:
Approach #3: Autonomy Last¶
My solution was to remove the timing of recall and memory creation from the agent's control. Upon receiving a message, the memories are automatically searched, with relevant ones being added to context. Every n messages, a memory is created3:
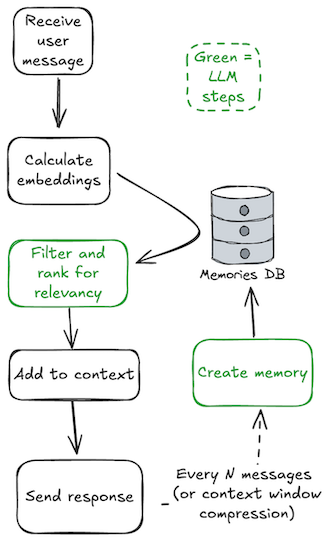
This made much more of the behavior of my program deterministic, and made it easier to reason about and optimize.
Autonomy Last¶
The "autonomy last" approach trades some of the magic of fully autonomous LLMs for predictable, reliable behavior that scales as your program grows in complexity. While my evidence is, (as I should have stated from the outset), vibes, I think this approach will lead to more maintainable and robust applications.
-
Rather than using agents to describe the genre of program under discussion, I'll be somewhat pointedly referring to them as programs. ↩
-
One problem I didn't have, thanks to litellm, was updating a lot of my code to support a different model API. ↩
-
Elroy also monitors for the context window being exceeded, and consolidates similar memories in the background. ↩