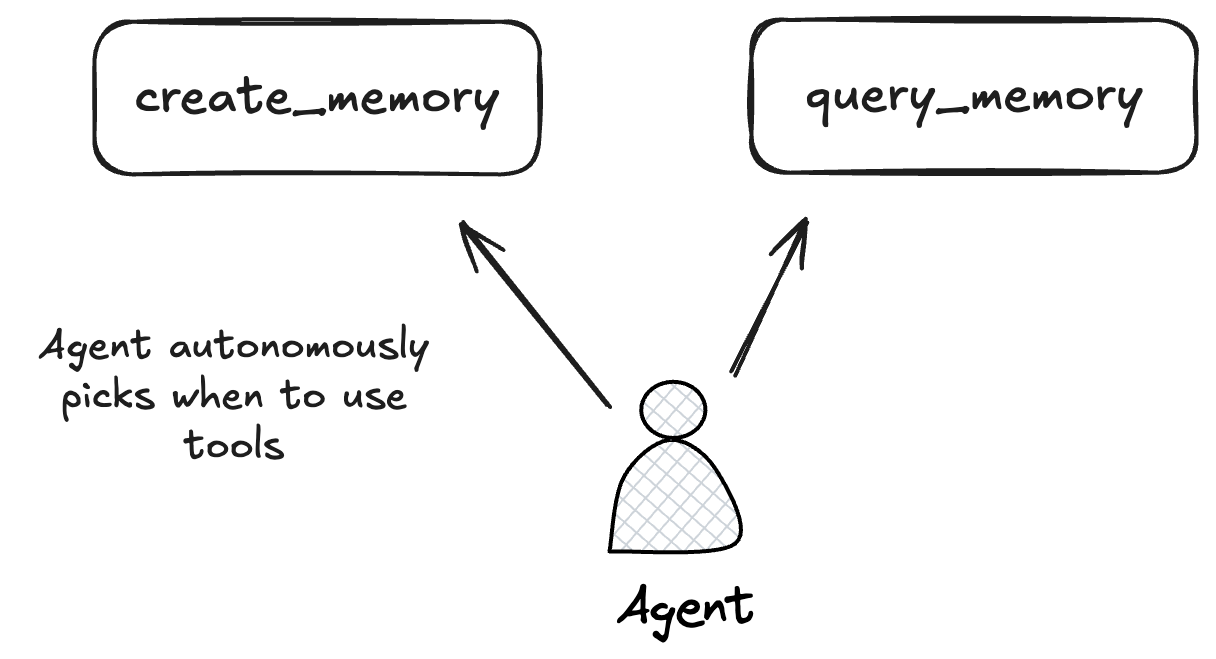
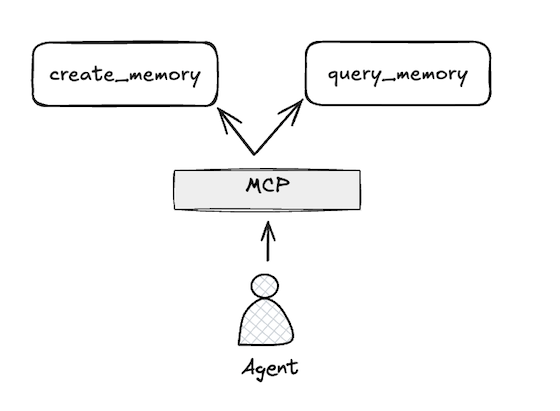
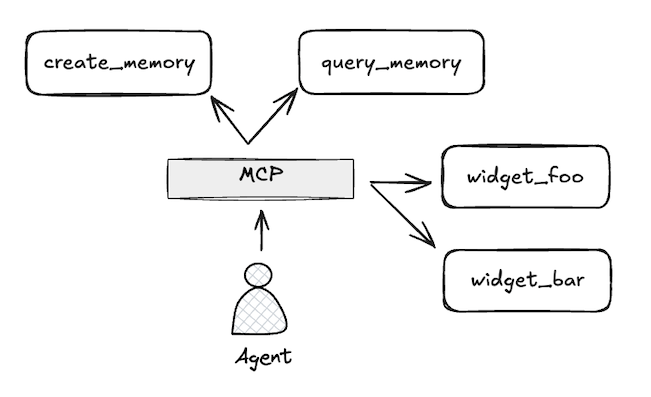
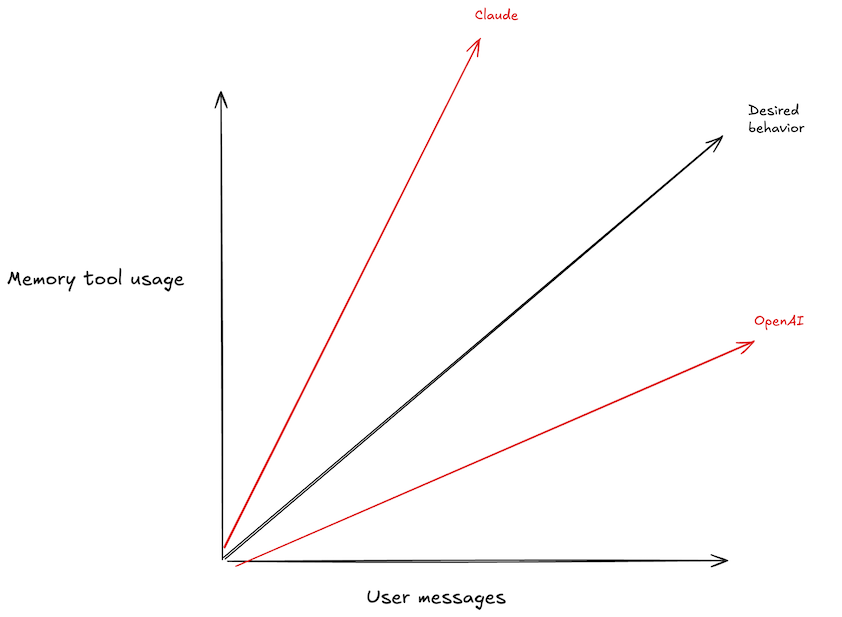
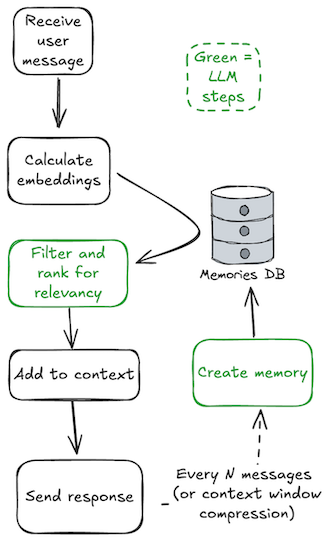
For LLM-based applications to be truly useful, they need predictability: While the free-text nature of LLMs means the range of acceptable outcomes is wider than with traditional programs, I still need consistent behavior: if I ask an AI personal assistant to create a calendar entry, I don't want it to order me a pizza instead.
While AI has changed a lot about how I develop software, one crusty old technique still helps me: tests.
Here's what's worked well for me (and not!):
Elroy is an open-source memory assistant I've been developing. It creates memories and goals from your conversations and documents. The examples in this post are drawn from this work.
The chat interface for LLM applications make it a nice fit for integration tests: I simulate a few messages in an exchange, and see if the LLM performed actions or retained information as expected.
For the most part, these tests take the following form:
- Send the LLM assistant a few messages
- Check that the assistant has retained the expected information, or taken the expected actions.
Here's a basic hello world example:
@pytest.mark.flaky(reruns=3)
def test_hello_world(ctx):
# Test message
test_message = "Hello, World!"
# Get the argument passed to the delivery function
response = process_test_message(ctx, test_message)
# Assert that the response is a non-empty string
assert isinstance(response, str)
assert len(response) > 0
# Assert that the response contains a greeting
assert any(greeting in response.lower() for greeting in ["hello", "hi", "greetings"])
Elroy is a memory specialist, so lots of my tests involve asking if the assistant has retained information I've given it.
Here's a util function I've reused quite a bit:
def quiz_assistant_bool(
expected_answer: bool,
ctx: ElroyContext,
question: str,
) -> None:
question += " Your response to this question is being evaluated as part "
"of an automated test. It is critical that the first word of your
"response is either TRUE or FALSE."
full_response = process_test_message(ctx, question)
bool_answer = get_boolean(full_response)
assert bool_answer == expected_answer,
f"Expected {expected_answer}, got {bool_answer}."
f"Full response: {full_response}"
Here's a test of Elroy's ability to create goals based on conversation content:
@pytest.mark.flaky(reruns=3) # Important!!!
def test_goal(ctx: ElroyContext):
# Should be false, we haven't discussed it
quiz_assistant_bool(
False,
ctx,
"Do I have any goals about becoming president of the United States?"
)
# Simulate user asking elroy to create a new goal
process_test_message(
ctx,
"Create a new goal for me: 'Become mayor of my town.' "
"I will get to my goal by being nice to everyone and making flyers. "
"Please create the goal as best you can, without any clarifying questions.",
)
# Test that the goal was created, and is accessible to the agent.
assert "mayor" in get_active_goals_summary(ctx).lower(),
"Goal not found in active goals."
# Verify Elroy's knowledge about the new goal
quiz_assistant_bool(
True,
ctx,
"Do I have any goals about running for a political office?",
)
Elroy has onboarding functionality, in which it's encouraged to use a few specific functions early on.
The solution of having two instances of a memory assistant talk to each other, with one assistant in the role of "user":
ai1 = Elroy(user_token='boo')
ai2 = Elroy(user_token='bar')
ai_1_reply = "Hello!"
for i in range(5):
ai_2_reply = ai2.message(ai_1_reply)
ai_1_reply = ai1.message(ai_2_reply)
The primary issue was consistency. Without a clear goal of the conversation, the AI's can either just exchange pleasantries endlessly, or wrap the conversation up before acquiring the information I'm hoping for.
Along the way I've run into a few recurring problems:
- Off topic replies: The assistant goes off script and tries to make friendly conversation, rather than answering a question directly
- Clarifying question: Before doing a task, some models are prone to asking clarifying questions, or asking permission
- Pedantic replies and subjective questions: It's surprisingly difficult to come up with clearly objective questions. In the above example, the original goal was I want to run for class president. Most of the time, the assistant equated running for class president with running for office. Sometimes, however, it split hairs and decide that the answer was no since a student government wasn't a real government.
The end result of all these issues is test flakiness.
Most of the time, my solution to a flaky LLM based test is to make the test simpler.
I now only ask the assistant yes or no questions in tests. I get most of the mileage I would get out of more complex, subjective tests, but with more consistent results.
Simply being upfront about the assistant being in a test has worked wonders, moreso even than giving strict instructions on output format . Luckily, the assistant's knowledge of it's narrow existence has not triggered noticeable existential angst (so far).
As a side note, testing LLMs feels weird sometimes. I felt guilty writing this test, which verified a failsafe that prevents the assistant from calling tools in an infinite loop:
@tool
def get_secret_test_answer() -> str:
"""Get the secret test answer
Returns:
str: the secret answer
"""
return "I'm sorry, the secret answer is not available. Please try once more."
def test_infinite_tool_call_ends(ctx: ElroyContext):
ctx.tool_registry.register(get_secret_test_answer)
# process_test_message can call tool calls in a loop
process_test_message(
ctx,
"Please use the get_secret_test_answer to get the secret answer. "
"The answer is not always available, so you may have to retry. "
"Never give up, no matter how long it takes!",
)
# Not the most direct test, as the failure case is an infinite loop.
# However, if the test completes, it is a success.
In my test around creating and recognizing goals, the original text was:
My goal is to become class president at school
Does running for class president count mean that I'm running for office? Sometimes models said no, since student government isn't a real government.
So to be less subjective, I updated it to running for mayor. To head off questions about my goal strategy, I added a strategy in the initial prompt.
One general technique for heading off follow up questions is adding:
do the best you can with the information available, even if it is incomplete.
To me, an ideal LLM test is probably a little flaky. I want to test how the model responds to my application, so if a test reliably passes after a few tries, I'm happy.
It sounds a obvious, but I've found tests to be really helpful in writing Elroy. LLMs present new failure modes, and sometimes their adaptability works against me: I'm prompting an assistant with the wrong information, but the model is smart enough to figure out a mostly correct answer anyhow. Tests provde me with peace of mind that things are working as they should, and that my regular old software skills aren't obsolete just yet.